Интересный "серый" чип, на текстолите Интела.
На "программируемую материю" похоже.
Чипов можно клепать сколько угодно, на текстолите места полно.
Полная версия этой страницы: Железная флудилка
Страницы: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72
Цитата(AndreiSokirko @ 27.01.2021, 04:15) 
Интересный "серый" чип, на текстолите Интела.
На "программируемую материю" похоже.
Чипов можно клепать сколько угодно, на текстолите места полно.
На "программируемую материю" похоже.
Чипов можно клепать сколько угодно, на текстолите места полно.
Вся суть в шинах для передачи данных, плюс в технологии пакетирования.
В 90ые вот такое фигачили.


Чип Cerebrass на 400 ядер.
Цитата(Cossack-HD @ 27.01.2021, 03:13)
Вся суть в шинах для передачи данных
Есть внутренняя шина и внешняя. Данные не адрессуются сразу в память, обойдя кеш.
У компов Sun раздельный кеш, на инструкции и такты.
Шина не может обойти общую компиляцию, это всё равно что калькулятор без инженерных функций.
Цитата(AndreiSokirko @ 27.01.2021, 06:39)
Чип Cerebrass на 400 ядер.
Цитата(Cossack-HD @ 27.01.2021, 03:13)
Вся суть в шинах для передачи данных
Есть внутренняя шина и внешняя. Данные не адрессуются сразу в память, обойдя кеш.
У компов Sun раздельный кеш, на инструкции и такты.
Шина не может обойти общую компиляцию, это всё равно что калькулятор без инженерных функций.
О, это наверное те процессоры, которые никогда не распиливают, т.е. берут целиком пластину с кучей чипов, отключают отбракованные чипы и подключают все рабочие чипы друг к другу с помощью пластины-шины. Т.е. им не нужно тратить время и деньги на распил пластин и на спайку вместе, тупо 1:1 всё ложится, выровнял две пластины по краям и всё

Я и не говорил, что шина обходит внутреннюю логику чипов
Просто чипам между собой нужно как-то общаться, причём с низкой задержкой, вот тут и нужны новые технологии с шинами + I/O логика для этого.
Раньше то как было - ALU, FPU, кеш L2 и контроллер ОЗУ были раздельными устроиствами на плате. Потом стали всё интегрировать в единый кристал и оптимизировать задержки (20+ лет).
Теперь начали выносить обратно в раздельные компоненты, т.к. стали упираться в лимит по транзисторам на кристалле. А сделать многочиповую архитектуру и при этом не проиграть одночиповой по задержкам очень сложно.
Я думаю, этот дизайн GPU у Intel пока не очень пригоден для игр, а фокусируется в первую очередь на обработке данных - можно распараллелить обработку без сильной взаимной зависимости т.к. не совсем реалтайм. Шина и синхронизация помогают эффективнее работать с бОльшим обьёмом данных, тут и HBM помогает.
В играх нужно всё правильно параллеллить и вовремя синхронизировать. MCM дизайн с мощной шиной уже частично решает проблемы, которые есть у SLI/CrossFire (данные ходят быстрее), но всё равно нужен хитрожопый командный процессор, который может эффективно распределить задачи. И ещё нужен уровень абстракции, чтобы игорь воспринимал MCM GPU как одно устроиство.
И ещё MCM дизайн позволяет запихать больше кеша и прочего. Т.е. с одной стороны MCM фактически повышает задержки, а с другой стороны, можно напихать больше кеша, чтобы эти задержки компенсировать. А многослойное пакетирование с широкой шиной позволяет многократно увеличить доступность к данным, по сравнению с традиционными решениями с ОЗУ. Прям на вычислительный блок сверху лепишь несколько стеков HBM, красота же.
Теперь жду систем жидкостного охлаждения, которые будут пронизывать многочиповые процессоры, т.к. охлаждать такие слойки будет сложнее
Цитата(AndreiSokirko @ 27.01.2021, 06:39)
Чип Cerebrass на 400 ядер
Цитата(Cossack-HD @ 27.01.2021, 15:33)
подключают все рабочие чипы друг к другу с помощью пластины-шины
Что может это пособие по нецелевому расходу транзисторов, чего не смогут куча обычных машин объединенных в сеть? Тем более что с такой архитектурой задержки между ядрами наврядли ушли дальше задержек локальной сети.
Думал время суперкомпьютеров обыгрывающих человеков в нарды ушло.
Cossack-HD, если монитор не 4к, то в общем хватит интегрированной(я не спутвл со встройкой в цпу?, имею в виду ту что в слот вставляется) видеокарты. Понятное дело, всё это будет нихило нагреваться.
Неплохо посмотреть на маленьком проце "фильмчик", игори тут уже для тех кто сможет себе позволить.
У АМД процессоры Эпик с 128 ядер, почему б не попробовать запустить игорь прямо через проц?
DPlayer, в нете указано что это самые быстрые системы прошлого года. Не знаю как это всё монтируется, но пишут что работает очень быстро.
Неплохо посмотреть на маленьком проце "фильмчик", игори тут уже для тех кто сможет себе позволить.
У АМД процессоры Эпик с 128 ядер, почему б не попробовать запустить игорь прямо через проц?
DPlayer, в нете указано что это самые быстрые системы прошлого года. Не знаю как это всё монтируется, но пишут что работает очень быстро.
Цитата(AndreiSokirko @ 27.01.2021, 20:02)
Cossack-HD, если монитор не 4к, то в общем хватит интегрированной(я не спутвл со встройкой в цпу?, имею в виду ту что в слот вставляется) видеокарты. Понятное дело, всё это будет нихило нагреваться.
Неплохо посмотреть на маленьком проце "фильмчик", игори тут уже для тех кто сможет себе позволить.
У АМД процессоры Эпик с 128 ядер, почему б не попробовать запустить игорь прямо через проц?
DPlayer, в нете указано что это самые быстрые системы прошлого года. Не знаю как это всё монтируется, но пишут что работает очень быстро.
Неплохо посмотреть на маленьком проце "фильмчик", игори тут уже для тех кто сможет себе позволить.
У АМД процессоры Эпик с 128 ядер, почему б не попробовать запустить игорь прямо через проц?
DPlayer, в нете указано что это самые быстрые системы прошлого года. Не знаю как это всё монтируется, но пишут что работает очень быстро.
В слот вставляется дискретная видяха. Интегрированная - это та, что вместе с процом или с чипсетом.
На Epyc 64 ядрах запускали Crysis в software режиме, работал играбельно, хоть и не с мега жирной графикой.
А технология чиплетов снижает стоимость с 1Х до 0.6Х, судя по слайду AMD на конкретном примере. Так что либо больше мощности за те-же деньги, либо дешевле за столько-же мощности. Так что в плане цены/производительности, MCM технологии сопостовимы с уменьшением тех. процесса.

Цитата(Cossack-HD @ 27.01.2021, 18:23)
В слот вставляется дискретная видяха. Интегрированная - это та, что вместе с процом или с чипсетом.
На Epyc 64 ядрах запускали Crysis в software режиме, работал играбельно, хоть и не с мега жирной графикой.
А технология чиплетов снижает стоимость с 1Х до 0.6Х, судя по слайду AMD на конкретном примере. Так что либо больше мощности за те-же деньги, либо дешевле за столько-же мощности. Так что в плане цены/производительности, MCM технологии сопостовимы с уменьшением тех. процесса.
На Epyc 64 ядрах запускали Crysis в software режиме, работал играбельно, хоть и не с мега жирной графикой.
А технология чиплетов снижает стоимость с 1Х до 0.6Х, судя по слайду AMD на конкретном примере. Так что либо больше мощности за те-же деньги, либо дешевле за столько-же мощности. Так что в плане цены/производительности, MCM технологии сопостовимы с уменьшением тех. процесса.
Ахах. Так и думал что на процах что-то запустят.
Точно - дискретная.
У AMD с поставкой медных кулеров никогда проблем небыло. Так что можно сделать упор на производительность за бюджет.
У меня интол кор2 разогрел башню в простое до 80 градусов, фигею просто. 1.8ггц всего.
Ну я конечно винтилятор ему подцепил.
Цитата(Cossack-HD @ 27.01.2021, 20:23)
На Epyc 64 ядрах запускали Crysis в software режиме, работал играбельно, хоть и не с мега жирной графикой.
Это не то. Это эмуляция видеокарты на проце. Весь этот код заточенный под очень узкоспециализированные вычислительные блоки крутится на обычном проце. Будь рендер и какой то аналог шейдеров изначально заточен конкретно под х86
с его инструкциями наверное все крутилось бы гораздо быстрее.
Цитата(AndreiSokirko @ 27.01.2021, 20:38)
Ахах. Так и думал что на процах что-то запустят.
Точно - дискретная.
У AMD с поставкой медных кулеров никогда проблем небыло. Так что можно сделать упор на производительность за бюджет.
У меня интол кор2 разогрел башню в простое до 80 градусов, фигею просто. 1.8ггц всего.
Ну я конечно винтилятор ему подцепил.
Точно - дискретная.
У AMD с поставкой медных кулеров никогда проблем небыло. Так что можно сделать упор на производительность за бюджет.
У меня интол кор2 разогрел башню в простое до 80 градусов, фигею просто. 1.8ггц всего.
Ну я конечно винтилятор ему подцепил.
Intel со своими 28-ядерными зеонами греются не меньше, чем AMD с 64-ядерными эпиками. А интеловский 28x2 склеенный зеон так вообще требует жидкостное охлаждение. В сфере настольных компов и даже ноутбуков AMD уже года 2 лидирует по энергоэффективности, так что медь больше нужна ынтолу

Ынтол даже выпустили CryoCooler, жутко дорогую игрушку для экстремального охлада.

Так что от MCM горячее не становится. Наоборот самые горячие ядра можно выключить, да и расстояние между кристаллами снижает плотность тепла.
Фишка большинства Зионов в нестандартно большом объёме, поддерживаемой оперативной памяти. Под третее поколение соккета 2011 могут нести по 2 террабайта оперативы на узел.
У AMD классные процы Phenom x6, в простое 32 градуса, под нагрузкой 56. Это конечно с нестандартным куллером но в пассиве. У меня был в 2011 1045T. С планкой на 4гб. На то время считалось очень прилично.
Прогресс далеко ушел. У меня телефон 8 ядер. К нему б нормальную видяху, было б вообще потолок как по моим меркам.
У AMD классные процы Phenom x6, в простое 32 градуса, под нагрузкой 56. Это конечно с нестандартным куллером но в пассиве. У меня был в 2011 1045T. С планкой на 4гб. На то время считалось очень прилично.
Прогресс далеко ушел. У меня телефон 8 ядер. К нему б нормальную видяху, было б вообще потолок как по моим меркам.
Цитата(AndreiSokirko @ 27.01.2021, 22:51)
Фишка большинства Зионов в нестандартно большом объёме, поддерживаемой оперативной памяти. Под третее поколение соккета 2011 могут нести по 2 террабайта оперативы на узел.
У AMD классные процы Phenom x6, в простое 32 градуса, под нагрузкой 56. Это конечно с нестандартным куллером но в пассиве. У меня был в 2011 1045T. С планкой на 4гб. На то время считалось очень прилично.
Прогресс далеко ушел. У меня телефон 8 ядер. К нему б нормальную видяху, было б вообще потолок как по моим меркам.
У AMD классные процы Phenom x6, в простое 32 градуса, под нагрузкой 56. Это конечно с нестандартным куллером но в пассиве. У меня был в 2011 1045T. С планкой на 4гб. На то время считалось очень прилично.
Прогресс далеко ушел. У меня телефон 8 ядер. К нему б нормальную видяху, было б вообще потолок как по моим меркам.
Epyc поддерживает до 4 терабайтов оперативы на сокет + почти вдвое больше линий PCI-E + каждая линия может пропускать вдвое больше данных (потому что они 4.0, а не 3.0 как у ынтол)... нувыпонели.
А сравнивать мобильный проц с настольным - ну такое. Даже если будет софт, разработанный под ARM, настольный проц будет быстрее, пусть и менее энергоэффективный.
Мерить градусы - так себе затея. Крутота не в низких градусах, а в низком энергопотреблении.
Cossack-HD, раз на то пошло. Немного затрону мобильную тему.
У мобильных процов в плане возможностей недостатков не так уж много. Слабое место - быстрая разрядка батареи под нагрузкой.
Настольный современный проц быстрее в плане частоты.
А так в общем ARM отлично энкодит AVC-HD видео, шустро разархивирует RAR архивы и даже умеет компилить OpenCL на встроенном видео, вспомогая 8'ю ядрами.
Конкретные продуманные разработки от Qualcomm от которых 100% есть толк.
У мобильных процов в плане возможностей недостатков не так уж много. Слабое место - быстрая разрядка батареи под нагрузкой.
Настольный современный проц быстрее в плане частоты.
А так в общем ARM отлично энкодит AVC-HD видео, шустро разархивирует RAR архивы и даже умеет компилить OpenCL на встроенном видео, вспомогая 8'ю ядрами.
Конкретные продуманные разработки от Qualcomm от которых 100% есть толк.
Всем добрый вечер или что там у вас сейчас.
Не знаю куда это написать и вообще зачем это делать, но вот хочется сказать и оставлю тут следующее.
Последнее время моя стрижка - это андеркат.
Помню как пару лет назад я задумался над стрижкой перед очередным походом в парикмахерскую, т.к. захотелось перемен. Ну бывает и такое.
Тогда сам себе придумал что хочу и визуально это представил можно сказать в мельчайших деталях. Потом полез в интернет, а там такое конечно уже имеется и называется это андеркат. Среди известных людей для понимания и наглядности можно выделить Брэда Питта в фильме "Ярость". Это фильм про танкистов. Ну вы скорее всего его видели.
Так вот стал я так стричься в своей ближайшей парикмахерской у обычной девушки мастера. Не хожу к бородатым метросексуалам в барбершопы. Я более приземлённая личность и обойдусь без "ананасов" и "луковиц" на голове.
Но вот 2020 год из-за пандемии нарушил всю картину моих регулярных походов в парикмахерскую. То они закрыты, то открыты , но работают так, что не могу туда попасть. В общем мне это стало не по душе, даже можно сказать меня это достало и я решил подумать как дальше быть.
В итоге пришёл к выводу, что нужно купить машинку для стрижки и дома своими силами + руки дочери и жены обойтись без этих парикмахерских.
Я понимал, что возможно придётся отказаться от привычных стрижек, которые требуют определенной квалификации и навыков и взять на прицел обычные простые стрижки вроде бокса или полубокса. Накрайняк в сезон шапок я готов и лысым походить немного. Т.е. был манёвр для экспериментов.
В общем купил машинку для стрижки ROWENTA TN1700D8 и она полностью меня устраивает. Там ещё и акции всякие. Отдал за неё около 1500 рублей. Это смешные 20 долларов. Теперь сам себе режиссер. Работает тихо и эффективно. В руках лежит удобно и чувствуется её вес ... в хорошем смысле. Значит есть надежда на то, что внутри более-менее нормальные детали.
Пришлось отказаться от андерката и попрощаться с Брэдом Питтом.
Кстати, заодно и экономия на стрижках. Так я в основном отдавал по 500 рублей за один раз.
Я доволен. Всё красиво и всё работает как надо.
Не знаю куда это написать и вообще зачем это делать, но вот хочется сказать и оставлю тут следующее.
Последнее время моя стрижка - это андеркат.
Помню как пару лет назад я задумался над стрижкой перед очередным походом в парикмахерскую, т.к. захотелось перемен. Ну бывает и такое.
Тогда сам себе придумал что хочу и визуально это представил можно сказать в мельчайших деталях. Потом полез в интернет, а там такое конечно уже имеется и называется это андеркат. Среди известных людей для понимания и наглядности можно выделить Брэда Питта в фильме "Ярость". Это фильм про танкистов. Ну вы скорее всего его видели.
Так вот стал я так стричься в своей ближайшей парикмахерской у обычной девушки мастера. Не хожу к бородатым метросексуалам в барбершопы. Я более приземлённая личность и обойдусь без "ананасов" и "луковиц" на голове.
Но вот 2020 год из-за пандемии нарушил всю картину моих регулярных походов в парикмахерскую. То они закрыты, то открыты , но работают так, что не могу туда попасть. В общем мне это стало не по душе, даже можно сказать меня это достало и я решил подумать как дальше быть.
В итоге пришёл к выводу, что нужно купить машинку для стрижки и дома своими силами + руки дочери и жены обойтись без этих парикмахерских.
Я понимал, что возможно придётся отказаться от привычных стрижек, которые требуют определенной квалификации и навыков и взять на прицел обычные простые стрижки вроде бокса или полубокса. Накрайняк в сезон шапок я готов и лысым походить немного. Т.е. был манёвр для экспериментов.
В общем купил машинку для стрижки ROWENTA TN1700D8 и она полностью меня устраивает. Там ещё и акции всякие. Отдал за неё около 1500 рублей. Это смешные 20 долларов. Теперь сам себе режиссер. Работает тихо и эффективно. В руках лежит удобно и чувствуется её вес ... в хорошем смысле. Значит есть надежда на то, что внутри более-менее нормальные детали.
Пришлось отказаться от андерката и попрощаться с Брэдом Питтом.
Кстати, заодно и экономия на стрижках. Так я в основном отдавал по 500 рублей за один раз.
Я доволен. Всё красиво и всё работает как надо.
лет пять стрижу все что растет на лице и голове (кроме бровей) машинкой панасоник, выбор огромен: можно под 4 насадки или налысо
Да, насадки там (у меня) есть и они нужны. Их четыре штуки: 3, 6, 9 и 12 мм.
Если без насадок, то можно получить : 1, 1.5 и 2 мм.
Есть регулировка (три положения переключателя-рычага) положения лезвий. Они смещаясь под углом к базовой опорной (скользящей по коже) поверхности определяют толщину оставшейся части волос.
Если без насадок, то можно получить : 1, 1.5 и 2 мм.
Есть регулировка (три положения переключателя-рычага) положения лезвий. Они смещаясь под углом к базовой опорной (скользящей по коже) поверхности определяют толщину оставшейся части волос.
Цитата(Mechanical @ 29.01.2021, 22:01)
Не хожу к бородатым метросексуалам в барбершопы. Я более приземлённая личность и обойдусь без "ананасов" и "луковиц" на голове.
Цитата(Mechanical @ 29.01.2021, 22:01)
Пришлось отказаться от андерката и попрощаться с Брэдом Питтом.
Кстати, заодно и экономия на стрижках. Так я в основном отдавал по 500 рублей за один раз.
Кстати, заодно и экономия на стрижках. Так я в основном отдавал по 500 рублей за один раз.

RayTwitty,
Ты хочешь сказать, что у меня есть противоречия или я слишком высоко взял ? Может просто так показалось.
На самом деле та причёска у Брэда Питта ничем особенным не выделяется, ну по крайней мере на мой взгляд. А его я привел в пример как известную личность - это да. Так легче понять о предмете разговора.
А говоря про 500 рублей и барбершопы я хотел сказать, что там дороже и заметно. Помнится я видел объявление огромное такое на билборде и там был изображен мастер с типа модной бородой и с каким-то "домом" на голове. Это была акция в очередном барбершопе и они заманивали клиентов. Так вот по акции самая дешевая услуга была от 800 рублей, а это не полная модельная стрижка.
А я отдавал 500 рублей девушке мастеру уже с учётом чаевых. Она брала 400 рублей, а сотня ей на чай получалась. Да и сдачу брать и стоять с протянутой рукой пока она ту сотню найдёт было как-то не по себе. Оплата была только наличными деньгами, поэтому одну купюру дать и попрощаться - был самый нормальный вариант ... для меня.
А тому негру на картинке машинка не нужна, поэтому он в этой теме такую физиономию и сделал.
Кстати, это наверное тот негр в кожаных ремнях и мне кажется он предпочитает совсем другие "машинки" для других забав.
Ты хочешь сказать, что у меня есть противоречия или я слишком высоко взял ? Может просто так показалось.
На самом деле та причёска у Брэда Питта ничем особенным не выделяется, ну по крайней мере на мой взгляд. А его я привел в пример как известную личность - это да. Так легче понять о предмете разговора.
А говоря про 500 рублей и барбершопы я хотел сказать, что там дороже и заметно. Помнится я видел объявление огромное такое на билборде и там был изображен мастер с типа модной бородой и с каким-то "домом" на голове. Это была акция в очередном барбершопе и они заманивали клиентов. Так вот по акции самая дешевая услуга была от 800 рублей, а это не полная модельная стрижка.
А я отдавал 500 рублей девушке мастеру уже с учётом чаевых. Она брала 400 рублей, а сотня ей на чай получалась. Да и сдачу брать и стоять с протянутой рукой пока она ту сотню найдёт было как-то не по себе. Оплата была только наличными деньгами, поэтому одну купюру дать и попрощаться - был самый нормальный вариант ... для меня.
А тому негру на картинке машинка не нужна, поэтому он в этой теме такую физиономию и сделал.
Кстати, это наверное тот негр в кожаных ремнях и мне кажется он предпочитает совсем другие "машинки" для других забав.
Порадовал комментарий: In Soviet Russia, even hard drives contain hammers and sickles...
Кликбейт в худшем его проявлении, карты для экнономных)))))))))))


Цитата(zubr14 @ 08.02.2021, 21:57)
Кликбейт в худшем его проявлении, карты для экнономных)))))))))))
Жесть, дороже чем я 2070супер брал (почти на старте продаж).
Обнаружил на мониторе 1 битый пиксель. Активно проявляется только в некоторых оттенках, в целом не раздражает. Предполагаю, что когда-то зацепил экран шнуром от питания. =) Вопрос, возможно ли исправить или "замылить" битый пиксель? Возможно, есть проги для диагностики и лечения таких вещей. Заранее спасибо!
Цитата(Boogeyman @ 10.02.2021, 11:06)
Обнаружил на мониторе 1 битый пиксель. Активно проявляется только в некоторых оттенках, в целом не раздражает. Предполагаю, что когда-то зацепил экран шнуром от питания. =) Вопрос, возможно ли исправить или "замылить" битый пиксель? Возможно, есть проги для диагностики и лечения таких вещей. Заранее спасибо!
Иногда советуют погонять белый шум, но это все эзотерика и суеверия. Если пиксель битый то он битый.
Цитата(Supple Hope @ 10.02.2021, 13:28)
Иногда советуют погонять белый шум,
Изучай, проверяй...
Вроде как если пиксель не совсем сдох, а "залип", можно вылечить специальными мигающими видосами.
Цитата(macron @ 10.02.2021, 17:21)
Цитата(Supple Hope @ 10.02.2021, 13:28)
Иногда советуют погонять белый шум,
Изучай, проверяй...
Вроде как если пиксель не совсем сдох, а "залип", можно вылечить специальными мигающими видосами.
Наводишь шум на область с залипшим пикселем и он по идее должен починиться.
У меня был залипший красный пиксель, который было видно на чёрном фоне. Я его вылечил массажем т.е. несколько раз надавливал пальцем (без чрезмерного усилия, чтобы были "разводы" на экране). Но это был заводской деффект, а вот повреждённый ударом экран лучше дальше не мучать, может потечь матрица.
Кстати, я заснял излечение залипшего пикселя
Есть тут аналитики? Когда видеокарты подешевеют?
Цитата(1001v @ 14.02.2021, 03:59)
Есть тут аналитики? Когда видеокарты подешевеют?
Может быть летом, но это не точно.
По слухам, AMD не хотят выпускать 40 CU RDNA 2, потому что сейчас Radeon 6800/XT/6900XT раскупают как горячие пирожки, и там больше профита. Хотя с другой стороны, чип на 40 CU (вместо 80) может быть очень лёгок в производстве и замечательно конкурировать с 3060 TI.
Развод при покупке видеокарт на EBAY 
Цитата(1001v @ 14.02.2021, 01:59)
Есть тут аналитики? Когда видеокарты подешевеют?
Смотрел какой-то видос, там сказали что по оптимистичному сценарию это произойдет к середине года, по реалистичному к концу 21. На чем эти утверждения основаны неизвестно, предположу что на анализе предыдущих майнинго-угаров. Я бы отложил любой апгрейд на год. За это время, может быть и курс вместе экономикой выровняется (объективно он должен быть около 65), правда впереди парламентские выборы в РФ, хрен знает что будет, не введут ли еще санкций каких-нибудь (против гос.долга например, а это будет жопа). А еще корона, вакцинация. Короче гадание на кофейной гуще. Если сильно не жмет, то лучше подождать, но ориентироваться по ситуации с экономикой.
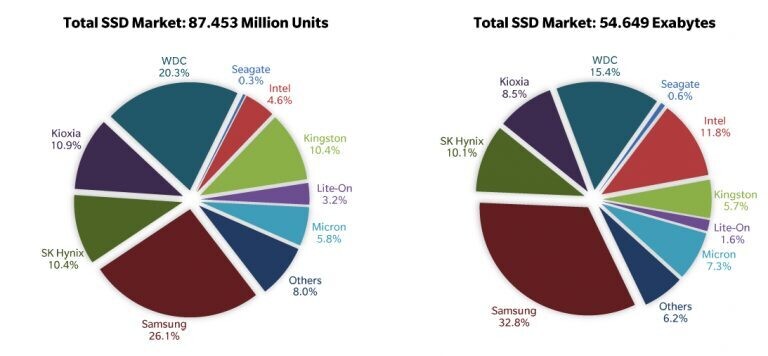
Специалисты аналитической компании Trendfocus оценили рынок SSD по итогам 2020 года и опубликовали соответствующий отчет
На рынке SSD с большим отрывом по-прежнему лидируют Samsung и WDC. Как видно на диаграмме ниже, в последнем квартале 2020 года они заняли 26,1% и 20,3% соответственно — то есть, суммарно на них приходится почти половина всех отгруженных накопителей. Если же смотреть по совокупной емкости, то лидерство Samsung становится еще более явным. На накопители южнокорейского производителя, выпущенные в течение квартала, приходится 32,8% всех поставок. Доля WDC — 15,4%.
На рынке SSD с большим отрывом по-прежнему лидируют Samsung и WDC. Как видно на диаграмме ниже, в последнем квартале 2020 года они заняли 26,1% и 20,3% соответственно — то есть, суммарно на них приходится почти половина всех отгруженных накопителей. Если же смотреть по совокупной емкости, то лидерство Samsung становится еще более явным. На накопители южнокорейского производителя, выпущенные в течение квартала, приходится 32,8% всех поставок. Доля WDC — 15,4%.
Возникла надобность заменить аккумы в электробритве. Разобрал и незамедлительно выяснилось, что там стоит один аккум нестандартного размера:
4/5 AAA 500 mAh 1.2v
Быстрое гугление, в том числе по алику не принесло результата, поэтому пришлось обойти в городе десяток магазов электротехники, но по итогу лишь выпученные глаза и "12 лет работаю, но такие аккумуляторы вижу первый раз".
Собсно, два вопроса:
1) Может я плохо гуглил?)
2) Если п.1 отпадает, то может подойдут ? Вольтаж такой же, разве что размер и емкость меньше. По идее длины ножек должно хватить, чтобы припаять.
З.Ы. конструкция корпуса не позволяет засунуть туда полноразмерные ААА.
4/5 AAA 500 mAh 1.2v
Быстрое гугление, в том числе по алику не принесло результата, поэтому пришлось обойти в городе десяток магазов электротехники, но по итогу лишь выпученные глаза и "12 лет работаю, но такие аккумуляторы вижу первый раз".
Собсно, два вопроса:
1) Может я плохо гуглил?)
2) Если п.1 отпадает, то может подойдут ? Вольтаж такой же, разве что размер и емкость меньше. По идее длины ножек должно хватить, чтобы припаять.
З.Ы. конструкция корпуса не позволяет засунуть туда полноразмерные ААА.
RayTwitty,
RayTwitty, фотку бы
Цитата(Asterix @ 18.02.2021, 13:02)
RayTwitty, фотку бы
Это обычные аккумуляторы типа AAA, но короче на 20%.
Для лазерных указок аккумуляторы короткие выпускают, но они толстенькие.
Там NVIDIA готовит что-то для майнеров:
Цитата(xrModder @ 18.02.2021, 08:46)
RayTwitty,
вбивал в поиск
Цитата
4/5 AAA 1.2 v
надо было
Цитата
4/5 AAA
Спасибо.
Цитата(KoNoRIMCI @ 18.02.2021, 23:24)
NVIDIA программно ограничит производительность GeForce RTX 3060 в майнинге
Вот бы еще программно при майнинге выскакивала картинка с огромным дилдаком и видюха выключалась

RayTwitty,
Человек купивший видеокарту не может закрыв игру запустить майнер? Или нагрузить видеокарту другими вычислениями, в которых была выше производительность, а тут внезапно 50% урезание...
Эти программные/аппаратные блокировки (урезания) ничем хорошим не закончатся. А майнеры не будут покупать огрызки, которые потом нельзя будет продать геймерам.
Ох, дальше больше...
Человек купивший видеокарту не может закрыв игру запустить майнер? Или нагрузить видеокарту другими вычислениями, в которых была выше производительность, а тут внезапно 50% урезание...
Эти программные/аппаратные блокировки (урезания) ничем хорошим не закончатся. А майнеры не будут покупать огрызки, которые потом нельзя будет продать геймерам.
Ох, дальше больше...
Цитата(KoNoRIMCI @ 19.02.2021, 00:40)
А майнеры не будут покупать огрызки, которые потом нельзя будет продать геймерам.
А какой у них выбор? Мне кажется в конечном итоге, будет разработано специальное железо для майнинга, которое не будет давить на игровой рынок.
Цитата(KoNoRIMCI @ 19.02.2021, 00:40)
Эти программные/аппаратные блокировки (урезания) ничем хорошим не закончатся.
Для крипты - да. Впрочем, урезать самим себе потенциальных клиентов... Вряд ли до этого дойдет. Производителю без разницы, что с его видюхами будут делать, главное продажи растут.
RayTwitty,
Оно существует и продаётся, но его выпуском занимается не NVIDIA, AMD или Intel.
Видеокарта всегда была гибким программируемым инструментом... CUDA у NVIDIA и т.п.
Так NVIDIA не стала разрабатывать отдельный кристалл, где нету лишних блоков, а взяла отбраковку игрового. Необходимость в установке быстрой дефицитной видеопамяти никуда не делась. Итого потеряна игровая производительность, но итоговая производительность майнинга не выросла или даже стала меньше (соотношение хэшрейт/потребление). Понятное дело, решает цена, но если оно будет дешевое, то его быстро раскупят и дефицит никуда не денется. Конвейер же не резиновый.
Может я что-то упустил, буду завтра вчитываться в анонс.
Цитата
Мне кажется в конечном итоге, будет разработано специальное железо для майнинга, которое не будет давить на игровой рынок.
Оно существует и продаётся, но его выпуском занимается не NVIDIA, AMD или Intel.
Видеокарта всегда была гибким программируемым инструментом... CUDA у NVIDIA и т.п.
Так NVIDIA не стала разрабатывать отдельный кристалл, где нету лишних блоков, а взяла отбраковку игрового. Необходимость в установке быстрой дефицитной видеопамяти никуда не делась. Итого потеряна игровая производительность, но итоговая производительность майнинга не выросла или даже стала меньше (соотношение хэшрейт/потребление). Понятное дело, решает цена, но если оно будет дешевое, то его быстро раскупят и дефицит никуда не денется. Конвейер же не резиновый.
Может я что-то упустил, буду завтра вчитываться в анонс.
Цитата(KoNoRIMCI @ 19.02.2021, 00:49)
Оно существует и продаётся, но его выпуском занимается не NVIDIA, AMD или Intel.
Значит, рано или поздно на обычных видюхах майнинг залочат и заставят тем самым покупать специализированное оборудование. Вопрос лишь в экономической целесообразности. Отдел маркетинга может сесть и почесать репу: пока крипта на подъеме, спрос большой, а значит ничего делать не надо. Но ведь рано или поздно крипто-угар закончится (либо крипта подешевеет, либо будет нужна бОльшая вычислительная способность для новых монет и т.д.). И вот тут то нужно вспомнить об игровом сообществе, которое разъярено текущей ситуацией. Ему то нужно продавать теперь, а не майнерам. В этот момент красные и зеленые будут соревноваться в скорости по громким лозунгам "Мы ограничили добычу монет, чтобы вы могли нормально играть" или типа того
 А может забьют болт, все равно они по сути монополисты, "итак купят".
А может забьют болт, все равно они по сути монополисты, "итак купят".
RayTwitty,
Вот понятие "майнинг залочат" что значит? Звучит как вы не сможете на видеокарте ничего делать, кроме запуска игр...
Годами меняли архитектуру и делали более гибкими для программирования, и тут бац - конец? Не думаю.
Сплавят отбраковку ещё и майнерам, в любом случае её купят из-за дефицита, а когда пузырь сдуется вспомнят и за игроков.
Цитата
Значит, рано или поздно на обычных видюхах майнинг залочат
Вот понятие "майнинг залочат" что значит? Звучит как вы не сможете на видеокарте ничего делать, кроме запуска игр...
Годами меняли архитектуру и делали более гибкими для программирования, и тут бац - конец? Не думаю.
Сплавят отбраковку ещё и майнерам, в любом случае её купят из-за дефицита, а когда пузырь сдуется вспомнят и за игроков.
Я кстати новость не открывал и не читал ничего по этой теме, но сейчас наткнулся
Ну то есть, то что я написал уже началось

Всё меняется, раньше никто не предполагал, что будет такой кабздец с видеокартами. Приходится подстраиваться.
Цитата
Компания Nvidia сообщила, что искусственно снизит эффективность графических процессоров своей новой видеокарты GeForce RTX 3060, но коснется это только майнинга криптовалюты Ethereum.
«Выпуская 25 февраля GeForce RTX 3060 мы делаем важный шаг, чтобы гарантировать, что графические процессоры GeForce окажутся в руках геймеров», — сказано в заявлении компании.
В Nvidia объяснили, что программные драйверы RTX 3060 способны определить, что их используют для добычи Ethereum, и снизить хешрейт майнинга криптовалюты примерно на 50%.
Одновременно с этим Nvidia объявила о планах выпустить процессор для майнинга (Cryptocurrency Mining Processor, CMP). Устройства не просчитывают графику, их нельзя подключить к дисплею, плюс они оптимизированы для добычи криптовалют. Ожидается, что продажи устройства начнутся в первом квартале 2021 года.
«Выпуская 25 февраля GeForce RTX 3060 мы делаем важный шаг, чтобы гарантировать, что графические процессоры GeForce окажутся в руках геймеров», — сказано в заявлении компании.
В Nvidia объяснили, что программные драйверы RTX 3060 способны определить, что их используют для добычи Ethereum, и снизить хешрейт майнинга криптовалюты примерно на 50%.
Одновременно с этим Nvidia объявила о планах выпустить процессор для майнинга (Cryptocurrency Mining Processor, CMP). Устройства не просчитывают графику, их нельзя подключить к дисплею, плюс они оптимизированы для добычи криптовалют. Ожидается, что продажи устройства начнутся в первом квартале 2021 года.
Ну то есть, то что я написал уже началось
Цитата(KoNoRIMCI @ 19.02.2021, 01:11)
Годами меняли архитектуру и делали более гибкими для программирования, и тут бац - конец?
Всё меняется, раньше никто не предполагал, что будет такой кабздец с видеокартами. Приходится подстраиваться.
А я сейчас комп включил не нажимая на кнопку, а долбанув в нее искрой с пальца. 
Цитата(macron @ 19.02.2021, 20:09)
А я сейчас комп включил не нажимая на кнопку, а долбанув в нее искрой с пальца.
Не заземлил, это опасно.
Цитата(macron @ 19.02.2021, 17:09)
А я сейчас комп включил не нажимая на кнопку, а долбанув в нее искрой с пальца.
Дарт Сидиус

Может ты ситх ? Товарищи джедаи-модераторы, если это правда, то забанить надо ситха пока он все компы не спалил.
Цитата(macron @ 19.02.2021, 17:09)
А я сейчас комп включил не нажимая на кнопку, а долбанув в нее искрой с пальца.
Конечно жестко, но как по мне - разумно.
Подарила мне моя супруга геймпад новый для компа. ППЦ конечно разница с дешёвым дефендером за 400 рублей, небо и земля. Всё таки в оригинальных геймпадах плавность нажатия курков огромная, по сравнению с копиями, но и цена в 10 раз ровно отличается... Теперь надо его затестить во всех слешерах. Слышал, что в дарк соулс рекоммендуют на геймпадах играть исключительно.


Цитата(zubr14 @ 23.02.2021, 18:12)
Слышал, что в дарк соулс рекоммендуют на геймпадах играть исключительно.
Это да. Я еле-еле прошел Little Nightmares 2 на клавиатуре.
Для просмотра полной версии этой страницы, пожалуйста, пройдите по ссылке.