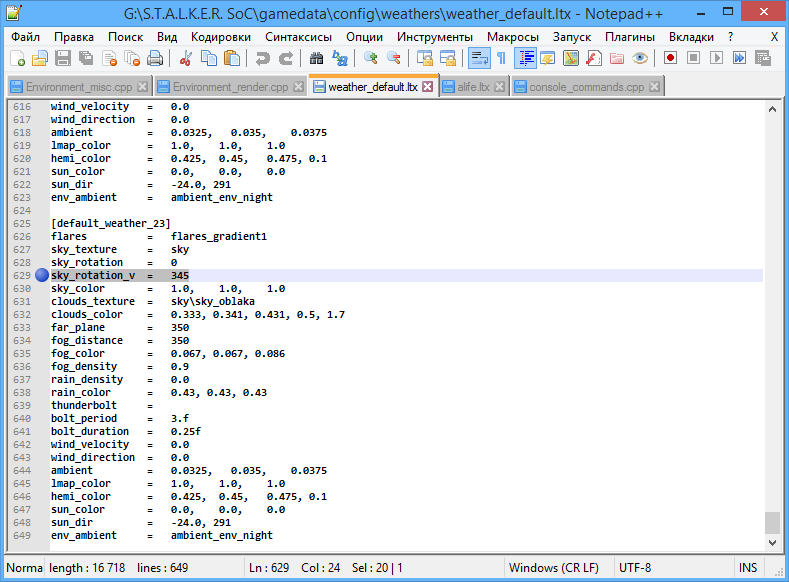
xrModder, абрам все по делу сказал, дополню его ответ и скажу свое решение. Во-первых это не баг, а тригонометрия, во-вторых как выше верно отметили небо крутится назад так как у тебя небо крутится от 345 до 0 (например), чтобы не крутилось нужно соответственно крутить 345 360 375 и т.д. до бесконечности. Я решил эту проблему под свои нужды следующим образом (мне надо чтобы просто куб по кругу ходил сутки и все), берем ротейшн первой секции и сравниваем его не больше ли он двух пи (так как он нам его в радианы переводит), и вторую секцию соответственно проверяем меньше двух пи, если подпадают секции под это условию, то ставим скай ротейшн форсед, в противном случае меняем плавно как обычно. Вот и все решение, четыре строки кода. Если нужны другие механики работы, то просто дорабатываешь формулу под свои нужды, ничего сложного там вроде вообще нету, код надеюсь не потребуется, это все таки до 9 класса в школе проходят

.
Цитата(Zagolski @ 21.10.2019, 17:26)

MLAA можно и на GPU сделать, кстати.
Мне больше нравится TAA 4х, быстрый и качественный. Ничего лучше не нашел в плане соотношения качество/ цена. В идеале лучше заюзать связку TAA + MSAA (TXAA по такому же принципу сделан), но тут уже из-за MSAA в скорости потеряем (тем более на отложенном рендере), да и лишних проблем в конвеер привнесем. Поэтому на деферред вместо MSAA лучше юзать MLAA. А так да, в такой связке сглаживание идеальное получается, взгляда не оторвать.
Так я нигде и не говорил, что млаа нельзя сделать на гпу
. Я говорил про философию млаа. Я гпгпу програмлю уже несколько месяцев и прекрасно знаю что можно делать с помощью него, млаа безусловно можно, но как бы смысл то какой.
Тхаа это не таа и мсаа, это блюреный мсаа. И короче, ради чего вообще тут, у меня получилось заюзать плюшки шейдерные и дико оптимзировать шейдер, написал отдельный специальный семплер и вс написал с помощью макета, это оптимизировало работу с памятью гпу ровно в шесть раз. И еще до кучи поскольку оглядываюсь на рендер ЗП увидел там проблему, там не зануляются макеты, из-за этого мы получаем рантаймовые ошибки при компиляции шейдеров (например если запустить ЗПшный рендер под дебагом сразу пойматься должна по идее), правится тривиально, в конце отрисовки надо занилять вертексные буферы и макеты. Я бы рекомендовал это сделать всем, без этого часть системных переменных нельзя юзать более одного раза без выпадения рантаймовых ошибок. Я правда пересмотрел кучу модов шейдерных на ЗП и данные подходы вообще никто не использует. Там усложняется существенно математика, но зато дикий плюс к оптимизации (примерно как там самая пресловутая оптимизация г-буффера), видимо всем плевать на какой-то эффективный шейдерный код, и там где можно юзать сырой инпут асемблер все чот выгоняют в вершинный буфер всякую фигню которая напрасно грузит гпу. Есть очень популярный мод, который этим очень грешит, но пальцем не будем показывать
.
Загольский, кстати, ты говорил что ты оптимайз г-буфера переделывал? Чо там менял? И еще я тут форвард чучуть попрограмил, скажи как ты там чо оптимизировал? Мне в голову пришло только упаковка четырех трехкомпонентных векторов в три четырехкомпонентных. Опять же там усложняется математика, но это классика для шейдерных оптимизаций. Интересны твои подходы, можно без конкретного кода, просто общую идею, думаю пойму. Форвард коеш такая себе тема, шаг влево шаг вправо и ботлнек, в сталкере все таки за отложик я бы свой голос отдал. И еще вопросец небольшой тени под пцф не переделывал (дх10 и выше онли)?
Цитата(Zagolski @ 15.10.2019, 13:03)
1. Ну во-первых на чн-овском не создается кэш шейдеров, что очень удобно при разработке, не нужно его все время чистить (на ЗП его можно отключить, но все равно).
2. На ЧН рендере качественнее палаллакс, больше объемность. Ну там и в шейдерах алгоритмы немного разные. А может просто в ЧН он есть на тех объектах, где в ЗП его убрали для оптимизации (порезали).
3. Самое главное, на ЧН рендере качественнее MSAA. На ЗП они все подпортили (видать для очередной оптимизации), не разбирался почему, но часть сцены не сглаживается вообще (на некоторых объектах остаются лесенки). Подозреваю, что это из-за msaa detect edge. На ЧН рендере сглаживаются полностью все объекты, в целом сцена выглядит куда качественнее со сглаживанием.
По первым двум пунктам категорически не согласен. Я даже не знаю, на мой взгляд это полный абсурд и как-то даже стремно серьезно это обсуждать. По третьему пункту согласен, если докопаешься - рад буду если поможешь. Там большая каша в определениях, я честно говоря до шейдеров еще не дошел, но так поверхностным взглядом такое ощущение что ломает оптимизация мсаа и на дх11 там тупо тонна шейдеров нифига не гладит так как берет везде один семпл (т.е. типа как бы и без мсаа было). Еще есть косяк шейдеров что отваливаются саншафты и чот с тенями какой-то треш. Возможно как-то криво минмакс сделали. Честно - до шейдеров тупо еще не добрался, чтобы их прям все капитально прошерстить, но поле деятельности уже вижу, данные там повыравнивать

.
Вообще по шейдерам большой разговор на деле. Я бы на самом деле занялся полным рефакторингом в свойственном мне стиле. Может есть желающие присоединится? Там можно все не только привести в порядок, но еще и неплохо думаю выйдет заоптимизировать, правда возможно немножко придется переделать пайплайн в области формирования константных буферов. Мне бы еще до конца разобраться чо за треш там с регистрами сделан, так на вскидку типа можно выгонять несколько переменных с одним именем и они ушиваются в массив, типо выгоняем две разных матрицы и типа можно получать значения как-то так my_matrix[0][2][2]. Кто в шейдерах сталкерских сечет помогите разобраться или лучше давайте вместе чонить замутим, польза же всем будет
.
И да, ссао/хбао на кс надо кому? Я тут чучуть шейдеры пытаюсь програмать
.
 Это к слову о говнокоде.
Это к слову о говнокоде.




 а можно об этом по-подробнее для тех кто ноль в графике?
а можно об этом по-подробнее для тех кто ноль в графике?


